Modelación estadística: La regresión lineal simple
Gabriel Cavada Ch.1
Statistical modeling: Simple linear regression
1División de Bioestadística, Escuela de Salud Pública, Universidad de Chile.
Cuando se observa un efecto, es inherente al pensamiento científico, buscar la o las causas que lo produjeron; esto es debido al estilo de pensamiento que poseemos de que “un conjunto de causas genera un efecto”. Al simplificar esta estructura cognoscitiva podemos pensar que una respuesta es generada por una causa; lo que podemos representar, cuando causa y efecto son medibles numéricamente, por una relación funcional:
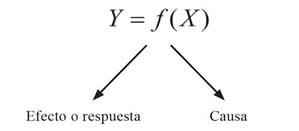
Particularmente, nos interesa modelar la respuesta cuando la relación funcional entre la respuesta y la causa es lineal, es decir, de la forma:
![]()
Obviamente, antes de ajustar un modelo como el propuesto es necesario saber si la variable respuesta se asocia linealmente con la variable independiente, cuando ambas se miden en n unidades de análisis, esto es, cuando se tiene una muestra de la forma:

Para ello, definimos el Coeficiente de Correlación de Pearson entre X e Y como:
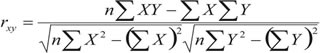
que mide el grado de asociación lineal entre X e Y, pudiendo demostrarse que:
![]()
y que si:
• rxy tiende a 1 la asociación es directa
• rxy tiende a -1 la asociación es inversa
• rxy tiende a 0 no existe asociación lineal
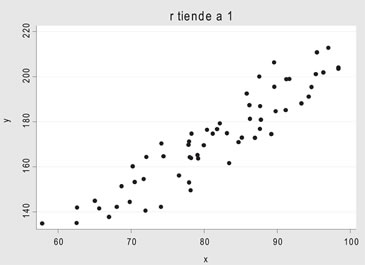
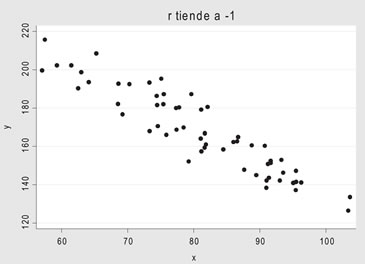
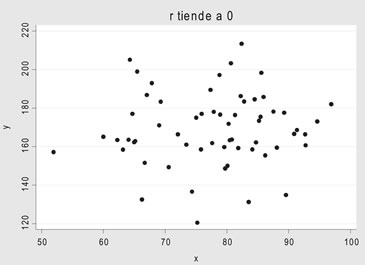
Estimación de la recta de regresión
I. El método de los mínimos cuadrados: Se basa en la minimización de la suma de los errores (distancia entre el valor observado de Y y el respectivo valor estimado), es decir suponemos que:
![]()
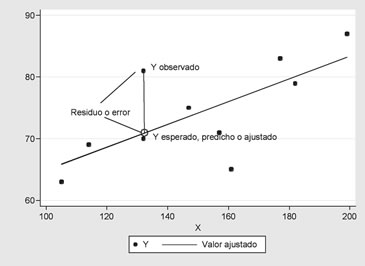
Se trata de minimizar la función:
![]()
Los valores que minimizan la función Q, se obtienen resolviendo el sistema de ecuaciones:
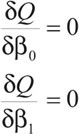
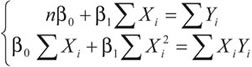
Estas ecuaciones reciben el nombre de ecuaciones normales, cuyas soluciones son:
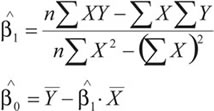
Que corresponden a los estimadores mínimo cuadráticos. Es fácil probar que:
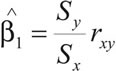
II. Estimación por máxima verosimilitud: Se basa en suponer que la respuesta Y condicionada a un valor de X sigue una distribución normal, cuya esperanza está sobre la recta de regresión y cuya varianza, σ2, es constante (homocedasticidad), en símbolos:
![]()
El supuesto anterior es equivalente a decir que los errores o residuos de la estimación siguen una distribución normal, cuya esperanza es 0 y su varianza es σ2, es decir:
![]()
Los estimadores para el intercepto y la pendiente de la recta, bajo estos supuestos, son idénticos a los estimadores conseguidos por el método de los mínimos cuadrados; la ventaja del supuesto distribucional es que podemos plantear inferencias y test de hipótesis sobre los parámetros estimados.
Una vez ajustado el modelo, la tabla de datos se extiende así:
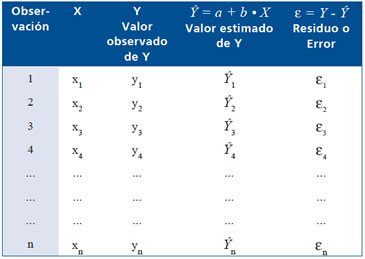
Una vez ajustado un modelo de regresión, es necesario conocer la calidad del mismo, para ello la variabilidad total de Y, que no depende del modelo ajustado, puede descomponerse en las llamadas “SUMAS DE CUADRADO” (SC), correspondientes a la varianza total, residual y debida al modelo o regersión:
![]()
SCTotal = SCResidual + SCRegresión
Los componentes de esta descomposición también reciben el nombre de Varianza total, no explicada y explicada, de modo que:
Varianza Total = Varianza no explicada + Varianza explicada
La varianza total es una cantidad fija, pues es sólo la varianza de la respuesta, no siendo así en la no explicada y explicada, pues dependen del modelo ajustado. Si el modelo ajustado fuera perfecto la varianza no explicada sería 0 y por consiguiente la varianza explicada sería igual a la varianza total. Este hecho nos lleva a definir como medida de la calidad del modelo el coeficiente de determinación como:
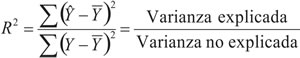
que en el caso de la regresión lineal simple coincide con r2 xy.
La descomposición de la variabilidad es posible resumirla en la conocida Tabla de Análisis de la Varianza (Tabla ANOVA)

Asociada a la descomposición de la variabilidad y por ende a la calidad del modelo, se tiene la siguiente dócima:
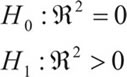
Cuya estadística de prueba es:
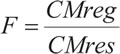 ~ F(1,n-2) (distribución F-Snedecor)
~ F(1,n-2) (distribución F-Snedecor)
La estimación de la varianza del error es:
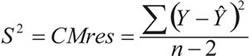
La interpretación de la pendiente de la recta de regresión
Si el modelo que se estima es de la forma:
y = α + β • X
Considerando:
a) y (X + 1) = α + β (X + 1) = α + βX + β
b) y (X) = α + β • Xy(X) = α + β • X
Restando a) y b)
Se obtiene:
y (X + 1) − y (x) = β
Es decir la pendiente de la recta, es el cambio de “Y” por unidad de “X”.
Ejemplo: Para los siguientes pares de tallas en centímetros y pesos en kilos, ¿Cómo y cuánto explica la talla al peso? (Ver tabla)
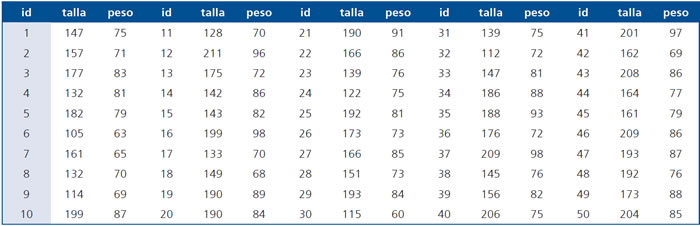
Para estos datos, el coeficiente de correlación es r = 0,7112 y la salida de STATA versión 10.1 para la estimación del modelo es:
Tabla ANOVA (Source: fuente de variación; SS: Suma de cuadrados; df: grados de libertad; MS: cuadrado medio; F: valor de la estadística F; Prob>F: p-value asociado a la dócima de existencia del modelo; R-squared: coeficiente de determinación y Root MSE: estimación de la desviación estándar residual).
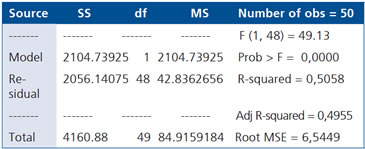
En negritas se muestra el p-value asociado a la dócima de existencia del modelo, es decir el coeficiente de determinación es significativamente mayor que 0.
Estimación de la pendiente e intercepto del modelo (Coef.: pendiente y cons es el intercepto, luego los errores estándar, la estadística t-student asociada a la dócima cuya hipótesis nula es pendiente igual a cero e intercepto igual a cero, los respectivos p-values y sus intervalos de confianza).
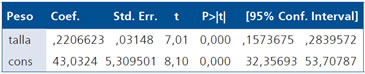
Estos valores señalan que la pendiente de la recta se estimó en 0,22, es decir que por cada centímetro de talla se espera un incremento en el peso de 0,22 kilógramos. Los p-values en negritas señalan que tanto la pendiente como el intercepto son significativamente distintos de 0.
La recta de regresión estimada es:
peso = 43,03 + 0,22 • talla
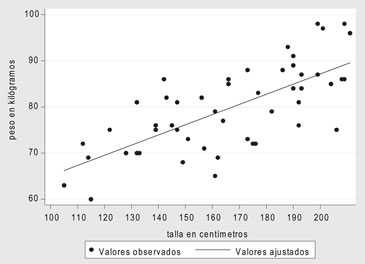
El siguiente gráfico describe la situación:
Diagnóstico en regresión lineal simple
Cuando se ajusta un modelo de regresión lineal simple, inicialmente sólo son creíbles las estimaciones de los parámetros, no así las inferencias hechas sobre ellos (test de hipótesis e intervalos de confianza). Para tener algún grado de certeza sobre la calidad de las inferencias, es necesario revisar el cumplimiento de los supuestos del modelo:
a) La normalidad de los residuos o errores: Luego de estimar el modelo se calculan los errores o residuos, que en este ejemplo llamaremos “resid”.
Un histograma de estos residuos se muestra en la siguiente figura:
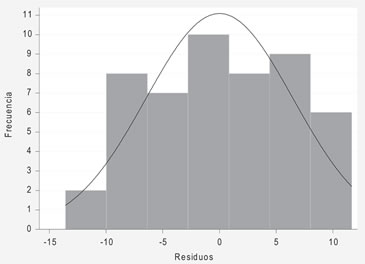
El histograma no deja claro que los residuos sean normales, sin embargo el test de Shapiro Wilk indica que no hay evidencia para decir que los residuos no son normales (p = 0,3315).
Sin embargo, la regresión lineal simple es “robusta” (esto es que se puede relajar el supuesto de normalidad de los errores) si es que estos tienen una distribución razonablemente simétrica, es decir si al rechazar la hipótesis nula en el test de Shapiro Wilk, aún se obtiene una distribución simétrica de los residuos, es decir una gráfico de cajas similar al siguiente:
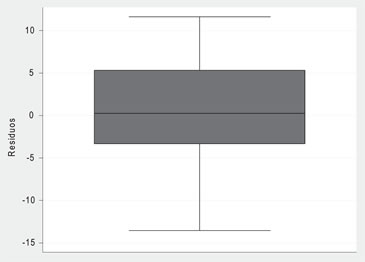
b) La homocedasticidad de los residuos o errores: Para probar este supuesto se comienza observando el gráfico entre los residuos y los valores predichos, en dicho gráfico no debería observarse ningún patrón de comportamiento:
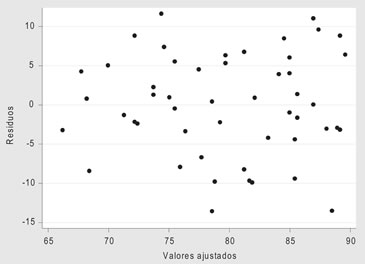
También podemos usar el test de herocedasticidad de Breusch-Pagan o Cook-Weisberg, cuya hipótesis nula es que la varianza de los residuos es constante, que en este caso entrega un p-value = 0,3269.
Ahora, podemos confiar en las inferencias del modelo.
Modelos linealizables
En muchas oportunidades una respuesta “Y” no depende linealmente de la causa “X”, sin embargo, la relación funcional, mediante una sencilla transformación matemática la convierte en una relación lineal a la cuál le podemos aplicar la metodología de la regresión lineal simple. En aplicaciones a la medicina aparecen los siguientes modelos:
1. Y = α • Xb, modelo de potencias, cuya forma se muestra a continuación:
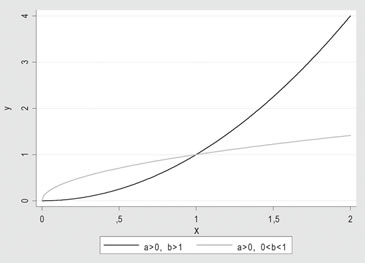
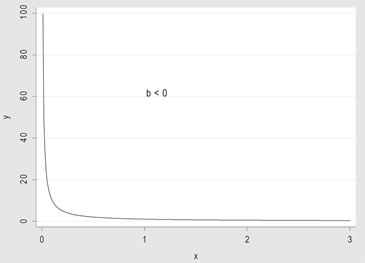
Tomando logaritmo al modelo:
1) ln (Y) = ln (α) + b • ln (X), los parámetros involucrados se estiman aplicando regresión lineal sobre el logaritmo de la respuesta y sobre el logaritmo de la causa.
2) Y = α • eb•X, modelo exponencial, cuya forma se muestra a continuación:
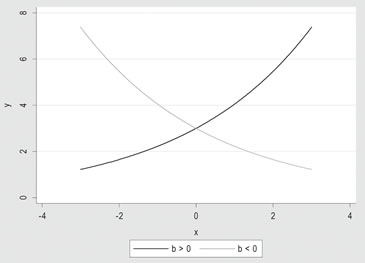
Tomando logaritmo al modelo:
ln (Y) = ln (α) + b • X, los parámetros involucrados se estiman aplicando regresión lineal sobre el logaritmo de la respuesta y sobre la causa.
Como se observa, la flexibilidad del modelo lineal simple es muy amplia, lo que lo convierte en un modelo muy recurrido y noble.