Modelación estadística: La regresión lineal simple.
Parte 2
Gabriel Cavada Ch.1,2
The meta-analysis, Part I: statistical foundations
1División de Bioestadística, Escuela de Salud Pública, Universidad de Chile.
2Facultad de Medicina, Universidad de los Andes.
Siguiendo la idea inspiradora de la regresión lineal simple, expuesta en el número anterior de esta revista, esto es que al observar un efecto y buscar la o las causas que lo produjeron, aceptamos ampliamente que este efecto puede ser producido por más de una causa, es decir, aceptamos la multicausalidad de una respuesta, concepto que nos acerca con mayor fidelidad a la realidad que estamos observando. Si la respuesta o efecto lo atribuimos a "p" posibles causas, la idea anterior la expresamos matemáticamente así:
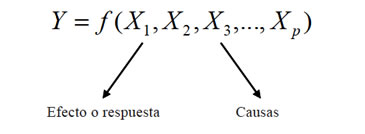
Nos interesa modelar la respuesta cuando la relación funcional entre la respuesta y la causa es lineal, es decir, de la forma:
![]()
o bien, si nos centramos en la i-ésima observación:
![]()
La estimación de los parámetros del modelo se obtienen por el método de máxima verosimilitud: Se basa en suponer que:
![]()
o equivalentemente:
![]()
Así la función de verosimilitud toma la siguiente forma:
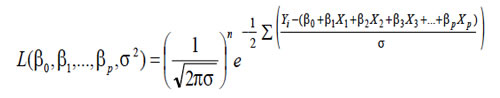
Al igual que en regresión lineal simple, se obtienen los estimadores de los parámetros del modelo. Sin embargo, es necesario agregar el supuesto de independencia entre los predictores; esta exigencia se conoce como "no colinealidad" o no multicolinealidad. De existir este problema, una variable que es en sí misma explicativa de la respuesta puede aparecer como no significativa ya que el efecto de alta colinealidad se refleja en una estimación con mucha varianza y por lo tanto con intervalos de confianza más anchos de lo que en la realidad son.
Una vez ajustado un modelo de regresión, es necesario conocer la calidad del mismo; para ello la variabilidad total de Y, que no depende del modelo ajustado, puede descomponerse del siguiente modo:
![]()
SCTotal = SCResidual + SCRegresión
Varianza Total = Varianza no explicada + Varianza explicada Se define el coeficiente de determinación como:
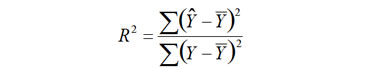
Como la respuesta está siendo explicada por más de
una variable predictora, no es posible definir un coeficiente
de correlación como el conocido "r" de Fisher, usado en
regresión lineal simple. Por ello estudiamos con detalle
el coeficiente de determinación R2. Sin embargo, el coeficiente
de determinación, aumenta en la medida que se
incorporan variables al modelo, sin aportar, necesariamente
una explicación plausible a la respuesta; por esta razón
es necesario corregir este coeficiente, por la cantidad de
predictores involucrados en el modelo; a este coeficiente de
determinación corregido se le llama R2 ajustado.
La descomposición de la variabilidad o Tabla ANOVA
es: (Tabla 1).
Tabla 1.

Asociada a la descomposición de la variabilidad y por ende a la calidad del modelo, se tiene la siguiente dócima:
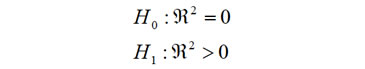
Es decir la hipótesis nula dice que el coeficiente de determinación es cero o equivalentemente el modelo de regresión lineal no existe, versus la hipótesis alternativa expresando que el coeficiente de determinación es positivo o decir equivalentemente que el modelo existe.
Cuya estadística de prueba es:
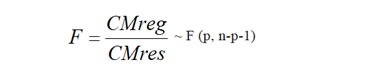
La F (p, n-p-1) indica el valor crítico en la distribución de Fisher-Snedecor.
Si la hipótesis nula es rechazada debemos concluir que a lo menos uno de los predictores involucrados en el modelo es significativo, en ningún caso significa que todos lo son.
La matemática involucrada en las estimaciones de los parámetros de la regresión múltiple es de mediana complejidad y no será detallada aquí.
Sin embargo, presentaremos un ejemplo ilustrativo que muestra una estrategia de análisis mínima usando la regresión
lineal múltiple:
Ejemplo ilustrativo:
En pacientes con antecedentes con infarto agudo al
miocardio, se desea explicar la presión arterial media
(pam=2) • (presión diastólica)/3-(presión sistólica)/3) a
través de las siguientes variables:

Estrategia de análisis
I. Descripción de la muestra
Se analizan 3.296 pacientes de los cuales 2.422 (73,48%)
son varones y 874 (26,52%) son mujeres.
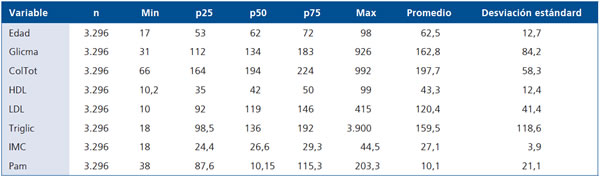
La Tabla 2 muestra predictores continuos y la respuesta, descritos por: el mínimo, los cuartiles, el máximo, el promedio y la desviación estándar.
Tabla 2.
Exploración de asociaciones de la Pam:
I. Como la variable sexo es dicotómica, la asociación con Pam se realiza mediante el test t de Student, encontrándose que las mujeres tienen una Pam significativamente más baja que los hombres (p = 0,0002)
II. La asociación de la respuesta y los predictores continuos se logra observando una "Matriz de Correlaciones", que muestra la respectiva correlación y el valor p que señala si la respectiva correlación es significativamente distinta de 0.
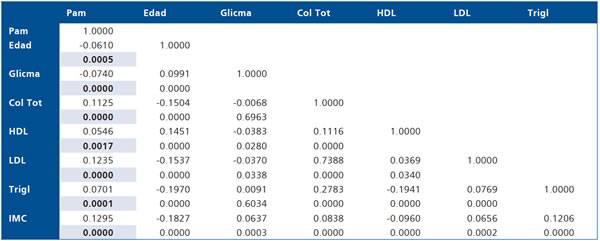
Los valores p en negritas indican que la Pam está correlacionada significativamente con todas las variables predictoras, pero además se observa que entre los predictores hay una fuerte evidencia de multicolinealidad.
III. Una forma de explorar el nivel de multicolinealidad es mediante el método de los valores y vectores propios de la matriz ![]() compuesta sólo por los predoctores; así, se genera un índice, , que representa el cuociente entre el valor mayor
y el valor menor propio de la matriz de correlaciones construida con sólo los predictores, y este se compara según el
siguiente criterio:
compuesta sólo por los predoctores; así, se genera un índice, , que representa el cuociente entre el valor mayor
y el valor menor propio de la matriz de correlaciones construida con sólo los predictores, y este se compara según el
siguiente criterio:
Si L < 30 hay poca colinealidad
Si 30 ≤ L ≤ 100 colinealidad moderada
Si L >100 hay colinealidad fuerte
El detalle de este procedimiento es complejo y requiere que el investigador recurra a un bioestadístico.
Para el ejemplo estudiado se encuentra como cociente de valores propios 8,8, lo que indica escasa colinealidad; esto permite estimar una regresión con todos los predictores continuos (sin incluir el género aún).
Al estimar el modelo se obtiene la siguiente salida computacional de STATA 10,1, que interpretamos a continuación:
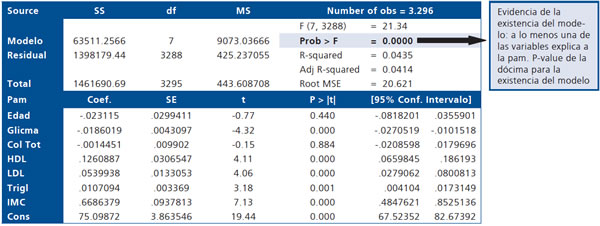
Los valores p en negritas indican que las respectivas variables explican significativamente a la Pam. La hipótesis nula es que el coeficiente respectivo es nulo.
Un modelo de regresión múltiple debe ser "parsimonioso", es decir debe explicar lo máximo posible con un mínimo de variables predictoras.
En este análisis se observa que ni la edad ni el colesterol total explican significativamente a la Pam: Si son sacadas del modelo ¿Se pierde capacidad de explicación? Esta respuesta la entrega el Test de Razón de Verosimilitudes (Likelihood ratio test), cuya hipótesis nula es que el modelo inicial y el modelo reducido tienen la misma capacidad de explicación:
Al realizar el Test de Razón de Verosimilitudes, cuya hipótesis nula expresa que el modelo completo (con todas las variables) tiene igual capacidad de explicación que el modelo reducido (al que se le han sacado las variables que no aparecieron significativas); determina un valor p = 0,7353 indicando que el modelo reducido explica igual cantidad de varianza que el inicial.
Por lo tanto, el modelo final es:
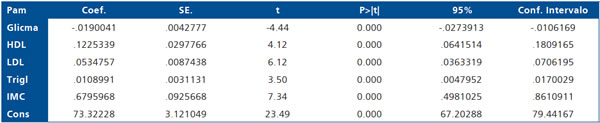
Es preciso notar que todas las variables son significativas, sin embargo, el impacto sobre la Pam ha variado respecto del modelo inicial.
Para interpretar un coeficiente, por ejemplo el que corresponde a IMC, tendríamos que decir:
- Si el modelo tuviese capacidad predictiva (R2 > 0,80) por cada unidad de IMC la Pam incrementa en 0,68 mmHg.
- Si el modelo tuviera fuerza asociativa, simplemente existe una asociación directa y significativa entre IMC y Pam (ya que el coeficiente es positivo).
El modelo final propuesto tiene un coeficiente de determinación de un 4,3%, que es bajo pero significativamente mayor a 0 (p = 0,0000), por lo tanto, la segunda conclusión es la más plausible.